IntelliJ IDEAからSpring Initializrを使う
Spring Initializrを使うと、Spring Bootのプロジェクト雛形を簡単につくれます。
Webで作った雛形を読み込むイメージだったんですが、IntelliJ IDEAから直接使えるみたいなのでやってみました。
Spring Initializr
New ProjectでSpring Initializrを選ぶ

作成するプロジェクトの設定を選ぶ
デフォルトのビルドツールはMavenで、言語はJavaですが、そこだけ自分好みにちょっと変えてます。
それ以外はデフォルトのまま。

利用するライブラリ(Dependencies)を選ぶ
とりあえず今回はSpring Web, Thymeleaf, Spring Boot Actuatorだけ選んでおく。

プロジェクト名と配置先を選択して完了
配置先はだいぶ適当。

この後、インデックスの更新とか、ビルドツールでの依存ライブラリ取得とか、諸々の初期化処理が実行されるのでしばらく待ちます。
試しに起動してみる
Run/Debug Configurationsがすでに出来ているので、実行するだけ
DemoApplicationがすでに出来ているので、とりあえず実行してみましょう。

コンソールにこんな感じで出力されるはず。

Actuatorを見てみる
http://localhost:8080/actuator/health/を見てみて、こんなjsonが返ってくれば、とりあえず起動まではOK。
{"status":"UP"}
テストも動かしてみる
DemoApplicationTestsというテストクラスも生成されているので実行してみると

テストが実行できることが確認できました。
【IntelliJ IDEA】Boolean method 'xxx' is always inverted
今日初めて見たんですが、IntelliJ IDEAでBoolean method 'xxx' is always invertedというメッセージに出会いました。
こんな感じ。メソッドの中身は超適当です。

メッセージの通りですが、呼び出し元が全部!で結果を反転している時に出てくるみたいですね。
これでInvert methodを選ぶと、変更後のメソッド名を何にするかというダイアログが出てきました。
とりあえずNotを入れた名前にしてみて、refactorを押すと、、

実装の中身が反転して、呼び出し元に付いてた!も全部外れてました。

メソッドの中身が複雑でも自動でリファクタリングしてくれるのかは試せてないですが、さすがIntelliJ IDEA。気が利いてますね。
【PostgreSQL】シーケンスなどの存在確認
久しぶりに書こうとすると、どうするんだっけってド忘れしてちょこちょこ調べている気がするのでメモ。
例えばシーケンスならこう。pg_classに対してSELECTする。
select 1 from pg_class where relname = 'sequence_name' and relkind = 'S';
relkindは、それが何なのかを表す。
- r: 通常のテーブル
- i: インデックス
- S: シーケンス
- v: ビュー
GraalVMってなんぞや
名前は聞くけどよくわかってないGraalVMについて、自分なりに整理してみます
公式情報を見てみる
とりあえず、まず公式情報。

トップで謳われているのは
という話ですね。この辺が大きい特徴なのかな。

もうちょっと、Key Featuresも見てみると、さっきと大きく変わらないけど、AOTコンパイルはさっきは無かったワードなのかな。
この先の、詳細な英語ドキュメントを初心者のうちから読むパワーはなかったので、雰囲気だけ抑えて、これ以降はいろんな日本語記事を見て理解したことをまとめます。
特徴
GraalVMの2つの特徴について。
- Polyglot
- Native
Polyglot
多言語を混ぜて使えるよ、という話。
Java, JavaScript (Node.js), Ruby, Python, C++, R あたりが使える。
んで、JavaからJavaScriptのコードを参照、みたいなことができる。すごい。
公式のデモはこちら。
Native
Key FeaturesにあったAOTコンパイル(Ahead-Of-Time, 事前コンパイル)によって、ネイティブで動作する、スタンドアローンなバイナリを作ることができます。
なおAOTコンパイル自体はJava9から導入されたもので、別にGraalVMの専売特許ではない。
いわゆる普通のコンパイルは、JITコンパイル(Just-In-Time, 実行時コンパイル)。GraalVMはJITコンパイルもできます。
バイナリのもうちょっと詳しい話は後述。
中核技術
GraalVMは、普通のJVMの発展版のようなもので、普通のJVMにできることは全部できる(はず)。
普通のJVMとは違う、GraalVMの中核技術には以下の3つが挙げられます。
- Graal
- Truffle
- GraalVM Native Image
Graal
普通のJVMがこんな感じになっているのに対して

(画像はこちらの10枚目)
GraalVMはこう
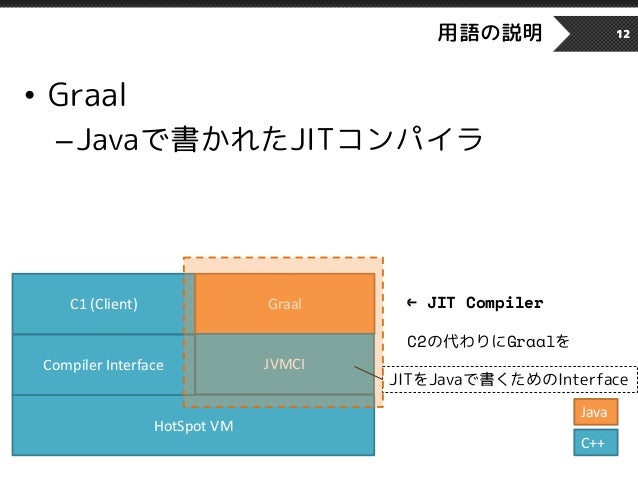
(画像はこちらの12枚目)
HotSpot VMをベースにしているのは同じで、C2コンパイラがGraalに置き換わっています。
Graal ≠ GraalVM で、Graal自体は、Java製のJITコンパイラのこと。Java10以降のOpenJDKで使えるらしい。(JEP 317)
Truffle
Truffleは言語実装用のフレームワーク。
この人のおかげで、GraalVMは複数の言語を動かすことができる。また、独自言語の実装もできる。
GraalVM Native Image
Nativeの項でも書いたとおり、GraalVMはネイティブで動作するバイナリ(Native Image)を作ることができます。
それの何が嬉しいかというと、Native Imageは仮想マシン上(JITコンパイル)ではなくネイティブで動くので、「起動が早くなる」「JVM言語のメモリ使用量が減る」などのメリットがあります。
逆に、OSの差異を吸収してくれるなどのJITコンパイルのメリットは得られなくなる。また、リフレクションや動的プロキシを使う場合には追加の作業が必要になるようです。
まとめ
複数の言語をまたいで、それぞれのライブラリなんかの資産を活用できるっていうのはすごく便利そうなので、動かしてみたいと思いました。(小学生並みの感想)
今回ほとんど触れられなかった速度に関しては、別に速くない、むしろ遅いっていう話もあるようだけど、その辺は今後に期待みたいな感じですかね。
参考文献
www.slideshare.net
困らない程度のJDK入門 from Yohei Oda
www.slideshare.net
Javaの新JITコンパイラ、Graalを解説 - InfoQ Javaの新JITコンパイラ、Graalを解説
マージコミットのcherry pick
こういうマージコミットをcherry pickする時の話

普通にgit cherry-pickしてみます
$ git cherry-pick -n 1adf377
怒られます。マージコミットは親が2ついるので、どちらから辿ればいいのか分からない、ということみたいです。
error: commit 1adf3776d12499e29a896d11a4d03846e7fc3c54 is a merge but no -m option was given. fatal: cherry-pick failed
-mに見て欲しい親のハッシュ(90a3900)を指定しましたが、
$ git cherry-pick -n -m 90a3900 1adf377
やっぱり怒られました。
error: option `mainline' expects a number greater than zero usage: git cherry-pick [<options>] <commit-ish>... or: git cherry-pick <subcommand> ...
調べたところ、親番号を教えないといけないみたいなので、git rev-parseで確認します。
$ git rev-parse 1adf377^1 90a3900fa17137dc88d0a4641e386e36763666f5 $ git rev-parse 1adf377^2 6d0fda8197e66cf3c6defa7ec616e61f12b37c13
今回は親番号が1の方を見てほしかったので、mオプションで指定します。
$ git cherry-pick -n -m 1 1adf377
これでうまくいきました。
参考
親番号の調べ方の情報元 stackoverflow.com
DBeaverでSQLのフォーマット
SQLをフォーマット(整形)したいときは、デフォルトだと ctrl + shift + f
